

escrito por Willian de Vargas
6 minutos de leitura

Conforme as iniciativas orientadas a dados crescem, a confiabilidade operacional desses pipelines começa a depender tanto da lógica implementada quanto da forma como sua execução é orquestrada. Foi nesse contexto que revisamos um modelo de orquestração responsável por monitorar variáveis operacionais críticas, como o volume de combustível utilizado e a quilometragem percorrida por frotas de veículos, e aplicar correções automatizadas com base em análises estatísticas sobre valores discrepantes. Migramos, então, de uma abordagem em que a orquestração era realizada no Azure Data Factory e o processamento executado por meio de notebooks no Databricks, para um modelo de orquestração e execução nativamente integrados à própria plataforma de processamento.
É importante destacar que o uso do Azure Data Factory como camada de orquestração para workloads executados no Databricks é um padrão arquitetural amplamente adotado e pode ser adequado em diversos contextos. No entanto, no cenário analisado neste caso, características específicas do modelo de execução e da forma como falhas eram tratadas introduziam limitações operacionais que impactavam diretamente a observabilidade e a confiabilidade do processamento analítico.
No modelo analisado neste cenário específico, não haviam mecanismos adicionais de propagação de falhas entre os planos de orquestração e processamento. Por mais que estivesse funcional do ponto de vista de acionamento e encadeamento de tarefas, essa separação levantava uma limitação crítca: falhas ocorridas durante o processamento nem sempre eram corretamente refletidas no plano de orquestração.
As execuções podiam ser concluídas com sucesso no orquestrador, mesmo quando etapas intermediárias, como a execução de notebooks no Databricks, haviam falhado logicamente. Em muitos casos, essas falhas não se manifestavam como erros de execução. Por exemplo, etapas de preenchimento de dados ausentes ou correção estatística podiam ser executadas sobre conjuntos de dados parcialmente atualizados sem gerar erros em tempo de execução, produzindo saídas inconsistentes, ainda que tecnicamente bem sucedidas do ponto de vista de execução. Como consequência, o fluxo seguia operando e materializando dados incompletos ou inconsistentes sem qualquer sinalização de erro.
Com isso, a falha deixava de ser um evento detectável e passava a ser um estado silencioso de degradação.
No contexto analisado, a separação entre o mecanismo de orquestração e de execução do processamento, sem sincronização explícita de estados entre essas camadas, criava uma divergência operacional importante: o sucesso da execução técnica deixava de garantir a integridade analitica dos dados produzidos.
Com isso, tabelas eram atualizadas, dependências eram acionadas e pipelines subsequentes eram executados com base em resultados potencialmente comprometidos. A falta de interrupção explicita do fluxo exigia validações manuais posteriores, tornando a integridade dos dados dependente de inspeção humana com muita frequência.
Nesse cenário, o monitoramento do pipeline deixava de ser uma fonte confiável sobre o estado real do processamento.
Ao coordenar externamente processos cuja lógica e dependências residiam internamente na plataforma de execução (Databricks), o modelo analisado passou a operar com dois planos de estado distintos.
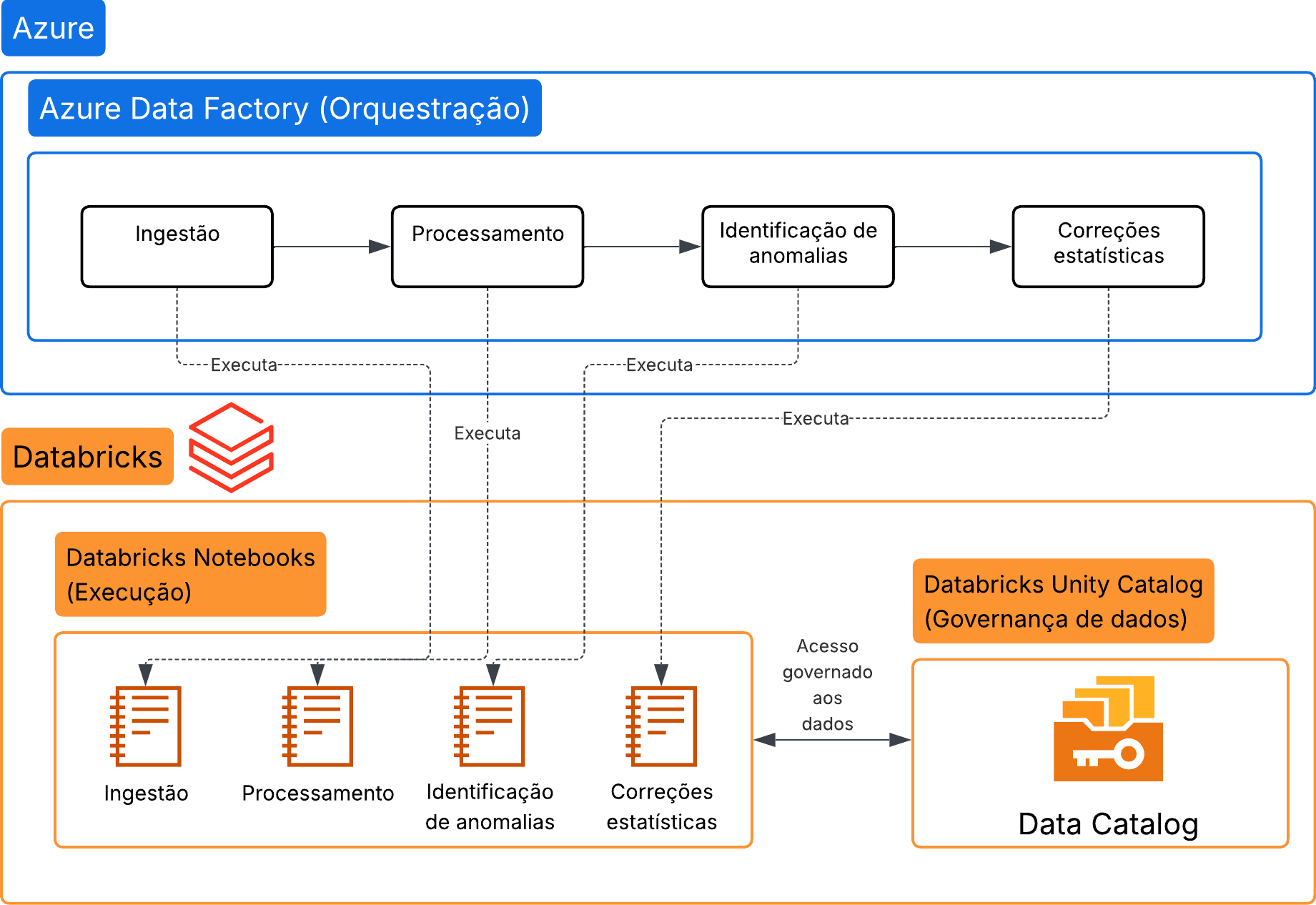 Modelo de orquestração desacoplada: A separação entre o Azure Data Factory e os Notebooks Databricks criava um vácuo de comunicação, onde falhas lógicas no processamento não eram propagadas para o orquestrador. Download do diagrama: (https://drive.google.com/file/d/1qCQSjjgD8hlFsGn2MjaBZgFaNqu0yT0L/view?usp=sharing)
Modelo de orquestração desacoplada: A separação entre o Azure Data Factory e os Notebooks Databricks criava um vácuo de comunicação, onde falhas lógicas no processamento não eram propagadas para o orquestrador. Download do diagrama: (https://drive.google.com/file/d/1qCQSjjgD8hlFsGn2MjaBZgFaNqu0yT0L/view?usp=sharing)
Sem um compartilhamento direto de contexto entre esses dois planos, o orquestrador tinha limitações em relação a visibilidade do comportamento real das tarefas executadas. O sucesso de uma atividade refletia apenas sua invocação e não necessáriamente sua conclusão integra.
O principal desafio deixava de ser lidar com falhas e passava a ser detectar elas de forma confiável dentro do modelo de orquestração atual.
Em muitos casos, essas falhas não se manifestavam como erros de execução computacional, mas sim como desvios lógicos no processamento que não geravam exceções ou códigos de erro. Como resultado, as tarefas eram concluídas do ponto de vista técnico, ainda que produzissem saídas incompletas ou inconsistentes, dificultando sua detecção pelo modelo de orquestração baseado exclusivamente no status de execução das atividades.
Considerando os requisitos operacionais deste pipeline específico, evoluímos o modelo ao migrar a orquestração para o Databricks Lakeflow Jobs, priorizando a integração entre orquestração e execução como forma de tratar as limitações observadas. Essa mudança não se restringiu apenas à substituição de ferramenta: também revisamos a lógica implementada nos notebooks de processamento, buscando melhorar a propagação de erros e introduzir validações que anteriormente não existiam, permitindo que falhas internas passassem a ser refletidas diretamente no status das execuções agora orquestradas nativamente na plataforma.
Assim, dependências entre tarefas passam a ser resolvidas nativamente dentro do mesmo ambiente responsável pelo processamento. O encadeamento entre as tarefas, a propagação de falhas e a interrupção do fluxo passam a ocorrer dentro de um único contexto de execução, permitindo que a execução e a orquestração deixem de operar como camadas independentes e passem a compartilhar o mesmo contexto operacional.
Nesse novo modelo, a interrupção do fluxo deixa de depender da interpretação externa de estados de execução e passa a ocorrer nativamente dentro do mesmo plano responsável pelo processamento analítico.
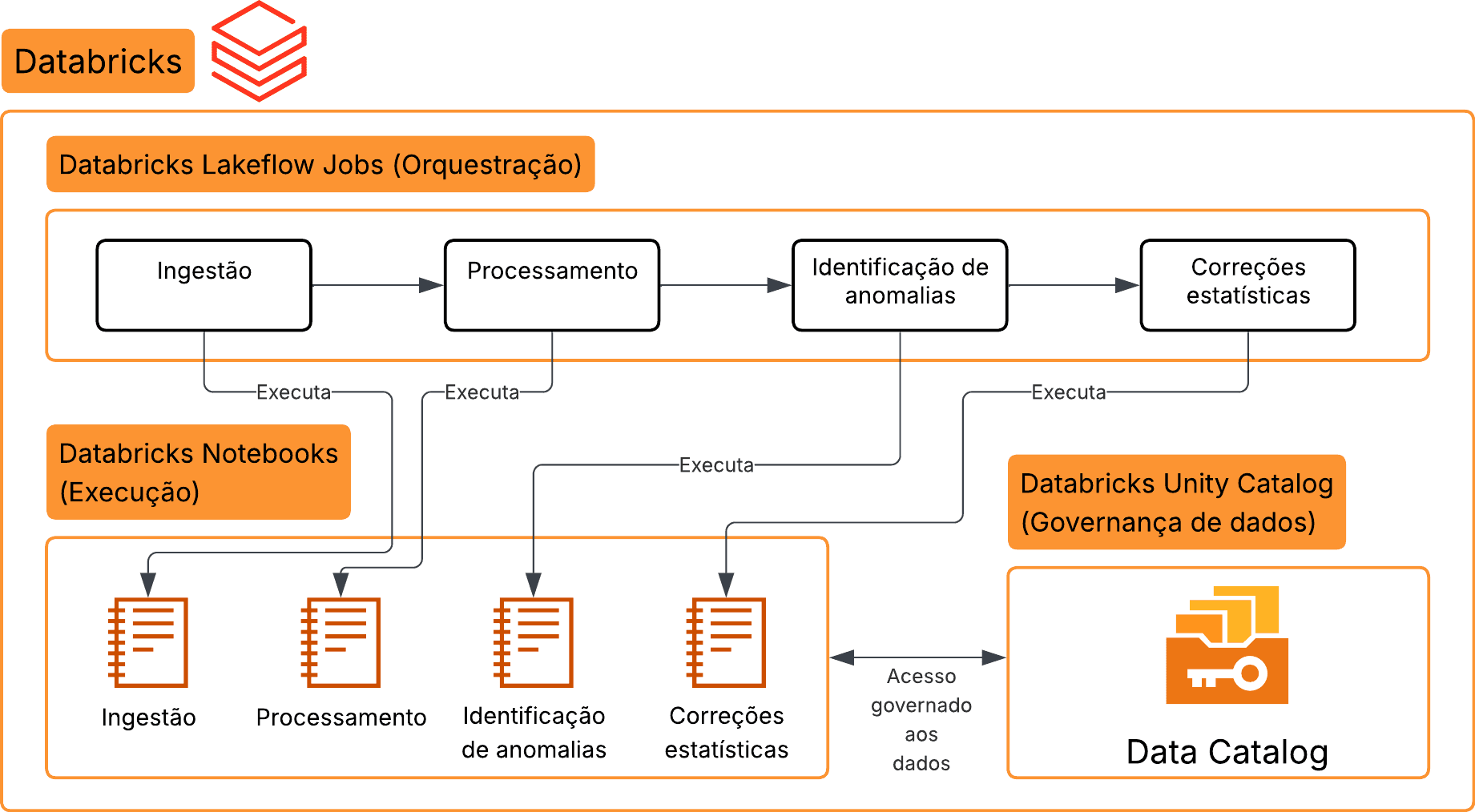
Modelo de orquestração nativa com Databricks Lakeflow Jobs: A unificação dos planos de execução e orquestração garante que o status do Job reflita a real integridade do processamento analítico. Download do diagrama: (https://drive.google.com/file/d/1Ec36jzjrDa4JWA2TkvvE9yMtQno48jFF/view?usp=sharing)
A adoção de Jobs nativos permitiu consolidar o ciclo de vida dos pipelines em um plano operacional único:
Com isso, a execução deixa de ser orquestrada externamente e passa a ser gerenciada como parte do prório processo analítico.
Ainda é importante notar que em cenários com múltiplas tecnologias ou forte dependência de integrações externas, modelos de orquestração desacoplados podem continuar sendo a alternativa mais adequada.
Com a orquestração integrada à plataforma de processamento e a revisão da lógica de tratamento de erros nos notebooks, falhas analíticas anteriormente não detectáveis passam a ser explicitadas como estados de execução, permitindo sua propagação ao longo do encadeamento de tarefas. Etapas comprometidas interrompem a execução subsequente, evitando que inconsistências se propaguem ao longo do fluxo.
A conclusão de um job volta a representar um indicador confiável sobre o estado dos dados produzidos, reduzindo a necessidade de validação manual e o risco de degradação prolongada. Logo, a falha deixa de ser silenciosa e passa a ser observável.
Isso reduz o risco de propagação silenciosa de inconsistências para etapas analíticas subsequentes, como agregações, modelos preditivos ou relatórios operacionais.
Ao alinhar orquestração e execução sob um mesmo contexto, o monitoramento deixa de depender da correlação entre múltiplos serviços. Logs passam a estar diretamente associados às tarefas executadas, e investigações deixam de exigir navegação entre planos distintos de controle.
O fluxo passa a ser operado como um processo coeso e não como uma sequência de etapas orquestradas externamente.
Mais do que estabilizar fluxos existentes, essa nova abordagem amplia as possibilidades de desenvolvimento e operação:
A conclusão de uma tarefa passa a depender não apenas da ausência de erros computacionais, mas também da validação de critérios analíticos definidos no próprio contexto de execução. Com isso, a confiabilidade deixa de ser um esforço manual e passa a fazer parte do próprio ambiente de execução.
Nesse cenário específico, os fluxos deixam de operar como integrações distribuídas entre serviços independentes e passam a ser tratados como processos analíticos executados sob um único contexto de execução e observabilidade, mais alinhado aos requisitos de controle de integridade deste pipeline.