

escrito por Kristy Noms
4 minutos de leitura

Para esta POC, utilizamos duas VMs com os seguintes recursos:
- CentOS 9
- PostgreSQL 17
- Database do StackOverflow versão Postgres (https://smartpostgres.com/posts/announcing-early-access-to-the-stack-overflow-sample-database-download-for-postgres/)
Primeiro precisamos criar o nosso usuário de banco que vai ser usado para conectar no primário e enviar os dados para a replicação via rede:
CREATE USER repl WITH REPLICATION ENCRYPTED PASSWORD 'xxxxxxxx';
Depois disso temos alguns parâmetros para configurar no postgresql.conf referentes a replicação:
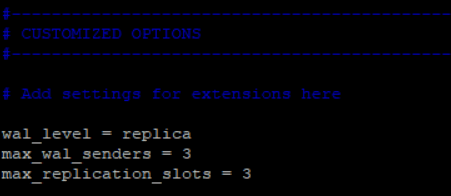
Uma rápida explicação, o max_wal_senders como default é definido como 10, porém não precisamos comprometer essas conexões no banco, assim definimos apenas o necessário para o funcionamento do nosso standby.
Aqui não precisamos colocar o parâmetro hot_standby pelo default ser ON, caso não fosse permitido leitura nessa réplica poderíamos colocar como off.
Alteramos também o nosso pg_hba.conf para permitir a conexão do servidor secundário no banco de dados.
Caso nossa replicação fosse file based não seria necessário essa liberação, visto que os WAL files seriam transferidos via sistema operacional.

Aqui limitamos o acesso por ip e usuário que criamos anteriormente.
Com essas etapas concluídas podemos fazer o restart do serviço do postgres para as alterações entrarem em vigor e assim finalizamos as configurações do servidor primário.
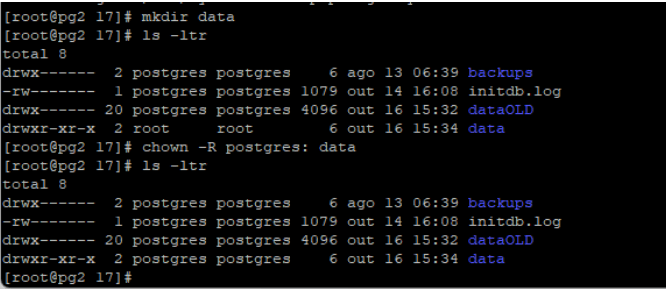
Como eu tenho uma instance vazia, primeiro eu vou renomear a pasta do PGDATA para poder fazer o backup/restore da minha base produtiva nele:

E criar uma pasta vazia mantendo as permissões do usuário postgres:
E ajustando as permissões para o postgres:
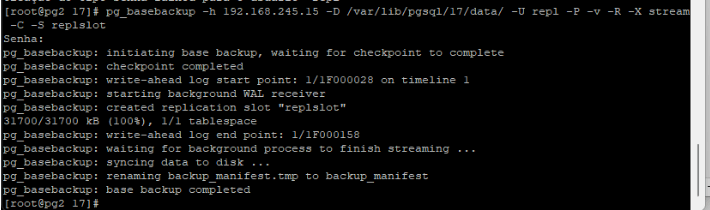
Feito isso podemos fazer o backup/restore usando o pg_basebackup:
pg_basebackup -h 192.168.245.15 -D /var/lib/pgsql/17/data/ -U repl -P -v -R -X stream -C -S replslot
Explicando esse comando que vamos utilizar:
-h: É o endereço do nosso primário
-D: O nosso PGDATA para jogar os arquivos
-U: O nosso usuário com conexão no primário
-P: É a barra de progresso
-v: Output do comando
-R: Esse aqui já diz que esse data directory vai ser um standby e insere no arquivo postgresql.auto.conf as configurações necessárias da replicação e cria o arquivo standby.signal
-X stream: Transfere os WALs junto do backup para garantir a consistência e inicializacao do nosso standby
-C: Aqui ele cria o nosso replication slot caso não tenhamos criado em prod anteriormente
-S replslot: É o nome do nosso replication slot.
OBS: O replication slot é opcional, porém criando ele nós garantimos que os WALs no primário só serão deletados depois de serem consumidos pelo standby, caso contrário podemos ter uma quebra do standby.
O lado negativo dessa configuração é que em caso de problema no standby ou se removermos a replicação precisamos corrigir antes de estourar o disco devido a retenção dos WALs.
Agora vamos rodar o comando :
Aqui os dois arquivos principais para nossa base entrar em standby são os arquivos standby.signal e as configuracoes no postgresql.auto.conf referenciando nosso primário.
No nosso comando do pg_basebackup ele já criou o arquivo e fez as alterações que precisava:

Pelo systemctl podemos ver o status
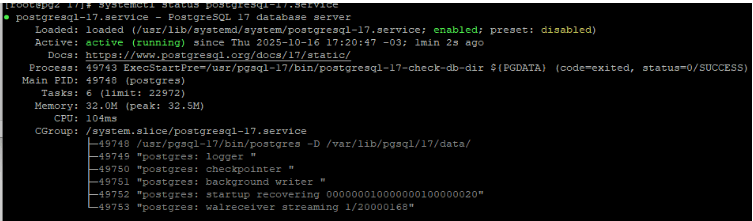
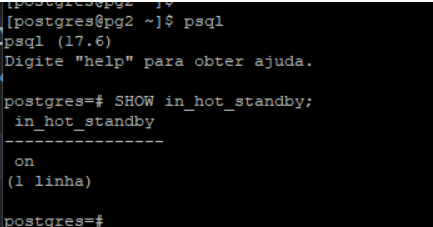
Validamos que nosso banco está como read only
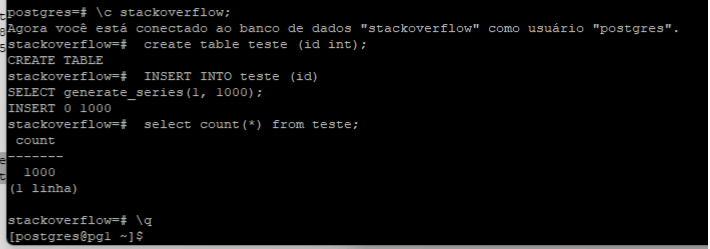
Criando uma tabela nova para validarmos o envio dos WALs:
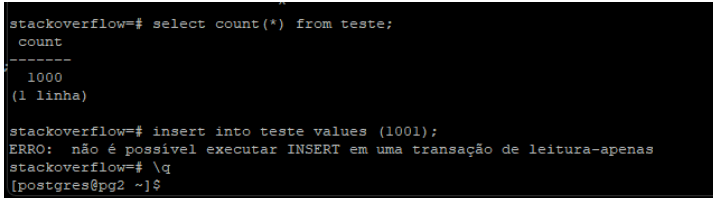
E em seguida no standby já temos a tabela replicada e se tentarmos inserir algo recebemos erro:
No primário pela tabela pg_stat_replication podemos ver as informações da replicação
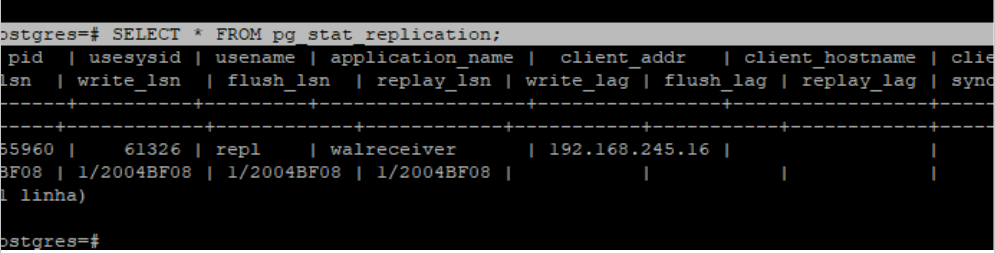
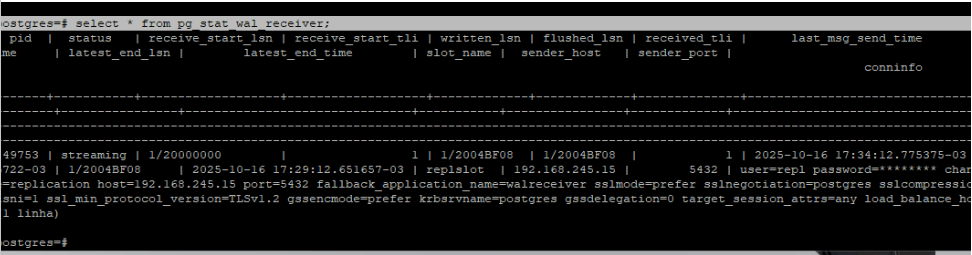
Para troubleshooting no standby usamos a tabela pg_stat_wal_receiver
Primeiro paramos o primário:

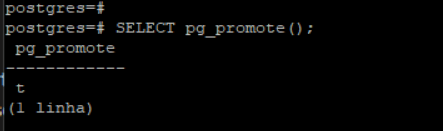
Com nosso standby validado agora podemos promover nosso servidor para ser nosso novo primário em um evento de desastre com o seguinte comando:
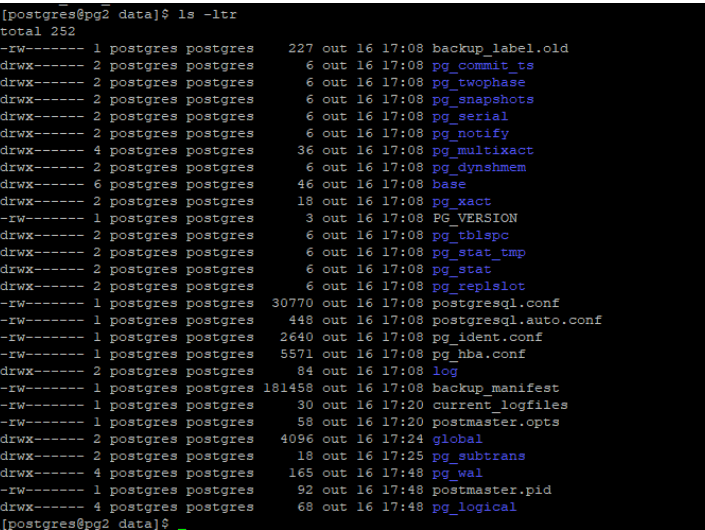
Verificando nosso diretório data vemos que foi removido o arquivo standby.signal:
E vemos que mudou para read write a base:

Nesse ponto poderíamos fazer um switchover e retomar o primário como standby mas não é o objetivo dessa POC.
É interessante em ambientes produtivos termos configurado a cópia do WAL para um disco separado e termos a cópia ou um mapeamento para o ambiente standby com o restore_command configurado, assim teremos um mix de streaming e file based replication, onde caso haja algum problema na rede, ainda podemos manter nosso standby sincronizado.
Importante cuidar o replication slot, caso a replicação seja removida precisamos eliminar ele para não ter retenção dos WAL infinitamente, ou caso precise fazer manutenção no servidor de replicação cuidar o espaço em disco.