

escrito por Marcelo Viana
5 minutos de leitura

A dobra de consultas (query folding) é a capacidade do Power BI de converter automaticamente as etapas de transformação feitas em M em uma consulta SQL, processando-as diretamente na fonte de dados, em vez de utilizar o mecanismo de transformações do Power BI. De acordo com o Microsoft Learn¹, a dobra de consultas pode ocorrer em três níveis:
Dobragem total de consultas: quando todas as transformações da consulta são enviadas de volta à fonte de dados, ocorrendo o mínimo de processamento no mecanismo do Power Query.
Dobragem parcial de consultas: quando apenas algumas transformações da consulta podem ser enviadas de volta à fonte de dados. Nesse caso, parte das transformações é executada na origem dos dados, enquanto o restante ocorre no mecanismo do Power Query.
Sem dobragem de consultas: quando a consulta contém transformações que não podem ser traduzidas para a linguagem nativa da fonte de dados, seja por falta de suporte às transformações ou por limitações do conector. Nessa situação, o Power Query extrai os dados brutos da fonte e executa todas as transformações necessárias no próprio mecanismo.
Para garantir a dobragem total de consultas, todas as transformações feitas em M precisam ser passíveis de tradução nativa para SQL. No meu caso, grande parte das consultas do fluxo de dados consistia em extensas transformações feitas em M, utilizando o conector do Databricks como fonte.
Entre essas transformações estavam filtragens de dados, criação de colunas calculadas, funções personalizadas, joins, substituição de valores, entre outras. Em cenários com muitas etapas de transformação e uso de funções personalizadas, como este, torna-se mais simples e eficiente converter todo o código para SQL, o que garantindo a dobragem total da consulta. Havia 4 consultas problemáticas, que somavam 78 etapas aplicadas em M que foram totalmente convertidas para SQL, garantindo a dobragem total das consultas. As demais consultas tinham menos transformações feitas em M, geralmente tipagens e filtros, essas também foram convertidas.
Utilizar apenas uma etapa de transformação, sendo ela uma query SQL, otimiza significativamente o processamento, pois essas operações são executadas diretamente no servidor de banco de dados de origem, neste caso o Databricks, aproveitando seus mecanismos de consulta altamente otimizados.
Ao processar os dados diretamente na fonte, aplicando filtros na própria query SQL, apenas o conjunto de dados final e já reduzido é enviado ao fluxo de dados. Isso é consideravelmente mais eficiente do que extrair todos os dados brutos e processá-los em memória utilizando código M.
É possível averiguar quando a dobra ocorre pela cor ao lado da etapa aplicada na interface do power query online, quando está verde em todas etapas, a dobragem total está ativada:
Algumas fontes como flat files (Excel e CSV), arquivos armazenados em object store como blob ou amazon s3, e databases NoSQL (como MongoDB e Cassandra) não dão suporte a dobra de consultas. Nestes casos as etapas de transformação feitas em M precisam ser reorganizadas e revisadas.
Nos fluxos de dados em questão, isso também ocorreu: existiam consultas conectadas a arquivos do SharePoint com mais de 25 etapas de transformação. Esse conector específico não suporta a dobra de consultas, porém foi possível reduzir em até 50% o número de etapas aplicadas redundantes ao longo do código. Havia tipagem de dados redundantes; etapas de filtragem de dados realizadas ao longo e ao final do código, que foram migradas para o início; múltiplas etapas aplicando a função Table.ReplaceValue que foram traduzidas para apenas uma; e funções personalizadas que tiveram seu código revisado. Manter um código simples e organizado contribui não apenas para a legibilidade, mas também para a performance.
Habilitar a atualização incremental reduz a quantidade de linhas processadas com base em um campo do tipo datetime no conjunto de dados. Além de tornar a atualização mais rápida, essa abordagem também diminui a quantidade de bytes lidos pelo fluxo de dados.
Em um dos fluxos de dados em questão, existe uma consulta com aproximadamente 20 milhões de linhas, que cresce diariamente, pois armazena snapshots diários. Para esse cenário, foi configurada a atualização incremental apenas nessa consulta, mantendo os últimos dois anos de histórico e atualizando diariamente apenas os últimos dez dias, com base em um campo datetime que registra a data de criação de cada snapshot.
Para habilitar a atualização incremental em um fluxo de dados de primeira geração, de acordo com as etapas documentadas no Microsoft Learn², basta abrir o fluxo de dados, identificar qual tabela/consulta que deverá ter a atualização incremental ativada e clicar no ícone destacado na imagem abaixo:
Após isso, a página de configuração da atualização incremental será exibida. Nela, deve-se escolher o campo datetime que será utilizado como base para o filtro, definir o período histórico a ser mantido e especificar quantos dias devem ser atualizados a cada execução.
A primeira atualização após a ativação da atualização incremental executará um full refresh, salvando os dados referentes aos últimos _ n_ anos definidos na configuração. Além dessas opções, é possível selecionar um segundo campo de data para avaliar mudanças específicas nas linhas. Esse campo geralmente é utilizado para fins de auditoria na fonte de dados e nem sempre está disponível. Quando configurado, dentro do intervalo de n dias que serão atualizados em cada execução, o fluxo de dados atualizará apenas as linhas que apresentaram alterações nesse segundo campo.
Por fim, também é possível configurar a atualização para considerar apenas períodos completos. Por exemplo, se o fluxo de dados é atualizado diariamente às 8h da manhã, mas os dados da fonte são carregados ao longo do dia, a atualização nesse horário resultaria em dados incompletos do dia corrente. Ao habilitar essa opção, apenas os dados de períodos já finalizados são processados, garantindo maior consistência nos resultados.
Em ambos casos deste artigo, era utilizado o fluxos de dados de segunda geração (Dataflow Gen 2). Esse recurso tem mais funções quando comparado com o fluxo de primeira geração, conforme a tabela abaixo:
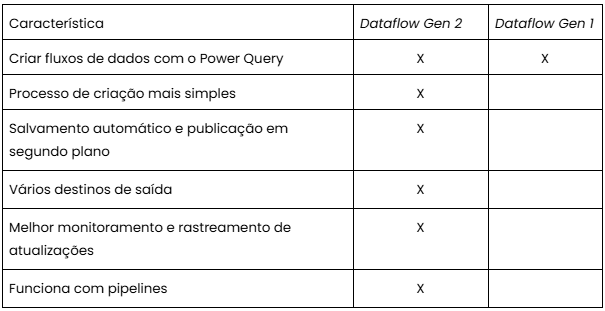

Algumas dessas funcionalidades podem ser cruciais dependendo da arquitetura do projeto no ambiente Fabric, como a possibilidade de conectar com pipelines e a capacidade de escolher o destino de saída, o que possibilita a ingestão de dados em Lakehouses do Microsoft Fabric. Outras funcionalidades são ótimas atualizações de “qualidade de vida” na experiência padrão dos fluxos de dados como o salvamento automático e publicação em segundo plano e os logs aprimorados de atualizações.
No entanto, em um estudo feito por Gilbert Quevauvilliers⁴, os fluxos de dados de segunda geração podem consumir em média até 700% a mais de capacity em uma importação de dados simples.
Neste caso, a economia de C.U´s utilizados pelo recurso era mais interessante que as melhorias feitas pela Microsoft nos fluxos de dados de segunda geração. Além disso, não tinha dependências com arquiteturas preestabelecidas em ambiente Fabric que gerasse alguma incompatibilidade com a troca para fluxo de dados de primeira geração. Visto isso, foram alterados ambos fluxos de dados para primeira geração ao invés de segunda geração.
Combinando todas essas técnicas em dois fluxos de dados distintos, foi observada uma redução na média de C.U.s utilizados durante a atualização, de 75.000 para 2.500 em um deles e de 60.000 para 2.000 em outro.
Referências